To win big in real estate market using data science – Part 3: Ensemble Modeling


Previously on CodeAStar: The data alchemist wannabe opened the first door to "the room for improvement", where he made better prediction potions. His hunger for the ultimate potions became more and more. He then discovered another door inside the room. The label on the door said, "Ensemble Modeling".
This is our last chapter on the "win big in real estate market with data science" series. You can click Part 1 and Part 2 for previous chapters respectively. Last time we made better predictions using model params tuning, now we want something "better than better". And the ensemble technique is the one we are looking for.
What is Ensemble Modeling?
Let' start with the very beginning, yes, what is ensemble modeling? In machine learning, ensemble is a term of methods running different models, then synthesizing a single and more accurate result. There are several types of ensemble modeling, like bagging, boosting and stacking. Some of the data models are already a form of ensemble as well, like Random Forest and AdaBoost models. But in this post, we will focus on stacking in ensemble.
Why Ensemble Modeling matters?
From our last "episodes", we got different improved predictions from different models: [Ridge Tuned Rid_t] Mean: 0.11255269 Std. Dev.: 0.012144 [Lasso Tuned Las_t] Mean: 0.11238117 Std. Dev.: 0.011936 [ELasticNet Tuned ElN_t] Mean: 0.11233786 Std. Dev.: 0.011963 [LassoLars Tuned LaLa_t] Mean: 0.11231273 Std. Dev.: 0.012701 [XGBoost Tuned XGB_t] Mean: 0.11190687 Std. Dev.: 0.015171
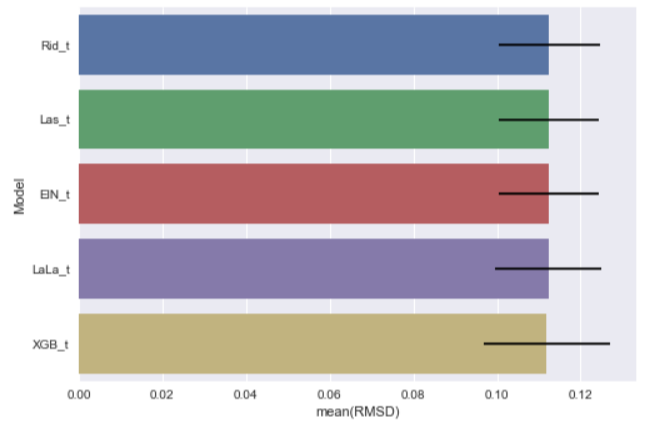
They all claim that they are the best models you'll ever have. In the past, we would run a K-fold Cross Validation and decide the best model among models. Likes running a battle royale, you let your finest warriors fight each other, until there is a sole survivor standing in the ring. What if, what if you hire your finest warriors as trainers and let them train a new warrior instead? The new warrior can learn the best parts from his/her trainers and become the even better warrior!
Does it sound like a good idea? Let's find out from the following demonstration:
The ground truth is: [100, 123, 150]
We have our finest warriors models, and here are their predictions and RMSDs:
Model A's prediction: [98, 110, 138] RMSD: 10.27943
Model B's prediction: [99, 120, 140]
RMSD: 6.0553
Model C's prediction: [107, 123, 153]
RMSD: 4.39697
Model D's prediction: [104, 130, 158]
RMSD: 6.55744
When we do our old K-Fold CV way, we can declare model C as our champion as it got the best 4.39697 RMSD score.
But now we use all four models to train a new model by averaging their predictions, then we have:
New model's prediction: [102, 120.75, 147.25] RMSD: 2.35407
After ensembling 4 models, the new model got a much better 2.35407 RMSD score!
Stacking in action
Stacking is a type of ensemble, we stack predicted results from different models to form a new data set. Then we use another model to learn from the new data set and make its own prediction.
To illustrate the stacking process:
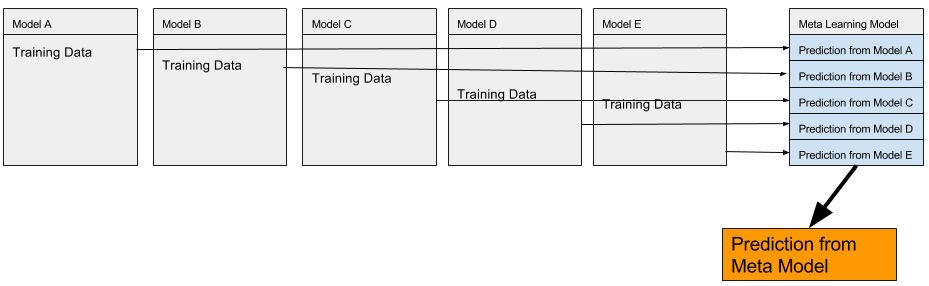
Talk is cheap, let's put our models in stacking action.
Last time, we tuned our models with parameters to get better results. This time, we stack our tuned models and a create new data set.
#our tuned models linearM = LinearRegression() ridM = Ridge(alpha=0.01) lasM = Lasso(alpha=0.00001) elnM = ElasticNet(l1_ratio=0.8, alpha=0.00001) lalaM = LassoLars(alpha=0.000037) xgbM = xgb.XGBRegressor(n_estimators=470,max_depth=3, min_child_weight=3, learning_rate=0.042,subsample=0.5, reg_alpha=0.5,reg_lambda=0.8)
We select 5 out of 6 models as our base models, then we pick the tuned LassoLars model as our meta learning model. i.e. The model that learns from the 5 base models. LassoLars model is selected because of its highest CV score.
base_models = [] base_models.append(lasM) base_models.append(ridM) base_models.append(xgbM) base_models.append(elnM) base_models.append(linearM)
meta_model = lalaM
First, we train our base models in 10 folds, get their predictions and use them as training data for our meta model.
stack_kfold = KFold(n_splits=10, shuffle=True) #fill up all zero kf_predictions = np.zeros((X_learning.shape[0], len(base_models))) #get the X, Y values X_values = X_learning.values Y_values = Y_learning.values for i, model in enumerate(base_models): for train_index ,test_index in stack_kfold.split(X_values): model.fit(X_values[train_index], Y_values[train_index]) model_pred = model.predict(X_values[test_index]) kf_predictions[test_index, i] = model_pred #teach the meta model meta_model.fit(kf_predictions, Y_values)
After the training of our meta model, we let base models predict with testing data. Then use our meta model to predict from base models' predictions.
preds = [] for model in base_models: model.fit(X_learning, Y_learning) pred = model.predict(X_test) preds.append(pred) base_predictions = np.column_stack(preds) stacked_predict = meta_model.predict(base_predictions)
Now we get the prediction from the meta learning model as stacked_predict.
One Step Further
The new meta learning kid trained by our top warrior models can predict better than his masters. What if we want an even better performance? Let's the kid and his masters join force and predict together. We make one step further for ensembling meta learning's result with our other top models' results. Their ensembling proportions are based on their CV performances. stack_n_trainers_prediction = stacked_predict *0.5 + xgb_pred * 0.3 + eln_pred *0.1+ rid_pred *0.1Then we submit the stack_n_trainers_prediction result to Kaggle. Ding! We got RMSD 0.11847 from official Kaggle Leaderboard, not bad.
Future of Data Science
Do you remember, on last post, we talked about tuning model parameters but without explaining the details? Similar thing happened on this ensembling topic also (although we did explain a bit, just not that deep). The reason behind this is simple, we don't really need it.
GridSearchCV and ensemble modeling are repeatedly process for machine to find a better match. Since it is "no free lunch" for which model parameters and combinations are "best for science". It turns out we keep validating different parameters and ensembling to find a better solution. For such trial and error task, it is more productive for using machine to handle it. When computing on machine becomes faster and cheaper time after time, we can assume machine will take over repeatedly tasks. Would data science be more like One-Punch Man story in the future? i.e. All of the stuff is finished by one punch click. We pass a data set to a machine, we click a button, sit back, let the machine do those trial and error tasks, and get the result.

It sounds attractive but it is possibly not the case we can see. We expect machine can help us find a better solution by sophisticated models and a lot of tries. It is only valid when you already have a solution for the machine to try and correct its predictions. Remember, it is no free lunch in optimization. So for our data alchemists, let's try brewing harder!
What have we learnt in this post?
- Introduction of ensemble modeling
- Usage of stacking in data science
- Possible future of data science
The whole source code of this trilogy can be found at https://github.com/codeastar/house_prices_regression_techniques .



