LGB, the winning Gradient Boosting model


Last time, we tried the Kaggle's TalkingData Click Fraud Detection challenge. And we used limited resources to handle a 200 million records sized dataset. Although we can make our classification with Random Forest model, we still want a better scoring result. Inside the Click Fraud Detection challenge's leaderboard, I find that most of the high scoring outputs are came from LightGBM (Light Gradient Boosting Machine, let's call it LGB in following post :]] ). Our hunger for knowledge should never stop. Let's find out why the LGB can win over other models.
LGB word by word explanation
LGB stands for Light Gradient Boosting. Let's we start with the first word, "Light". LGB developing team claims that LGB is fast in model training and low in memory usage. Like every developer in the planet, his/her product is always the best in the world. Then who LGB developers are? Microsoft. If you are as big as Microsoft, well, you do have the right to say something like that. (What about Internet Explorer, Zune, Windows Mobile and MSN messenger?)
Microsoft's LGB team provides a list of comparisons on how well LGB can out-perform XGB (eXtreme Gradient Boosting). Which XGB is another top winning machine learning model in current days. From the information provided by the LGB team, LGB is around 100% faster than XGB and uses only 25% of XGB's memory, on same data science challenges.
Then we go for another word, "Gradient". It is a changing process, starting from an initial status to a complete status. So, what are we going to change? We can find the answer on the B of LGB.
"Boosting". Boosting is a step to make something great again (does it sound familiar?). In machine learning, we use boosting to make weak learners great again. Then we have another question, what are "weak learners" there? Weak learners are models with high bias and low variance. (Remember the bartender in "Do you have a dog?" comic?)
Gradient Boosting
The term "Gradient Boosting" is a way to make weak learners becoming a good model. We start working from our first weak learner model and get the first round of predictions. Then we have our first error residuals (e1) by subtracting prediction values (y1) from actual values (y0). i.e. e1 = y0 - y1
Now we go for our next round of predictions, this time we fit the model with the residuals (e1) and get the a new set of prediction values (ye1). Our final prediction for this round (y2) will be previous prediction (y1) plus prediction using the residuals (ye1). i.e. y2 = y1 + ye1
Then our new residual (e2) will be actual values (y) subtracting round 2 prediction (y2), i.e. e2 = y0 - y2
We use the second residual (e2) to fit our third model and repeat the above steps. We stop when our model returns close to 0 residual after certain rounds of training. Then we are making a good model step by step from a weak model.
LGB and XGB in action
Microsoft have mentioned how LGB is superior than XGB on their GitHub page. Well, you know, I am a long time Microsoft's products user, I know I have to find out the truth myself.
We use the Click Fraud Detection dataset in a Kaggle 17 GB ram kernel for our own LGB and XGB comparison. First, we define our LGB and XGB models with following settings:
import lightgbm as lgb lgb_model = lgb.LGBMClassifier(learning_rate = 0.1, num_leaves = 65, n_estimators = 600) import xgboost as xgb xgb_model = xgb.XGBClassifier(learning_rate=0.1, max_depth = 6, n_estimators = 600)
Since the XGB model uses a depth-wise algorithm while LGB model uses a leaf-wise algorithm, we set the XGB model with max_depth = 6 to compare with LGB model with num_leaves = 65 (65 = 2 ^ 6 + 1).
Here come the results:
[table id=5 /]
It is obvious that XGB out-performs LGB in accuracy under the same settings. But, Microsoft is right for 2 things: LGB is fast in speed and light in memory usage. While XGB needs 2 hours to handle 30 million records, LGB just needs 15 mins. And LGB can use 10% memory of XGB to do the same task, which is way impressive.
Since model tuning is an important part in machine learning, a fast and light model is definitely an advantage for us to get a better outcome.
LGB and XGB in action, part 2
Now we switch to our next testing round, a smaller dataset, the Iowa House Prices dataset. This time, we use regressor models and run 30 and 100 -fold cross validation with following settings: lgb_model = lgb.LGBMRegressor(learning_rate = 0.05, num_leaves = 65, n_estimators = 600)
xgb_model = xgb.XGBRegressor(learning_rate=0.05,
max_depth = 6,
n_estimators = 600)
And here come the results again:
[table id=6 /]
In a smaller dataset, XGB runs better than LGB in term of speed, accuracy and memory usage. When we train our models more, we have a more accurate XGB model and a less accurate LGB model.

Actually, it is a feature of gradient boosting. Unlike other decision tree models which use level-wise growth algorithm during model training.
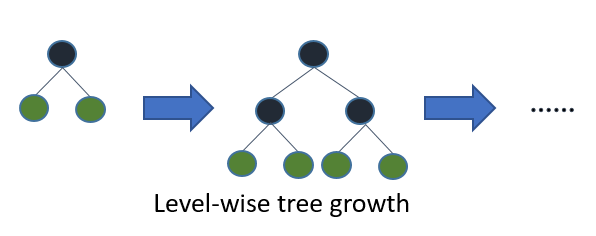
(image source: https://github.com/Microsoft/LightGBM/)
LGB uses leaf-wise algorithm instead. When the dataset is smaller, it is sensitive to variations and may create extra leafs, making it is overfitting for testing data.
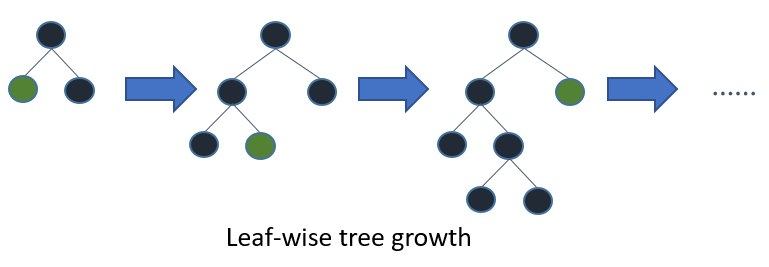
You may ask, why there is no such thing on XGB, as it is a gradient boosting model as well? Yes, XGB is a gradient boosting model, but unless explicitly set, XGB uses level-wise algorithm on smaller dataset.
Conclusion
Both LGB and XGB are powerful and winning models in data science competitions. For larger dataset, if you have enough time and resources, go XGB. Otherwise, LGB would be a better choice for tuning and tweaking. For smaller dataset, let's go XGB way to avoid LGB's overfitting.
What have we learnt in this post?
- Overview of LGB
- What is Gradient Boosting
- LGB and XGB comparison
- LGB's overfitting on smaller dataset



